Notes Extractor
Notes Extractor von cooper team
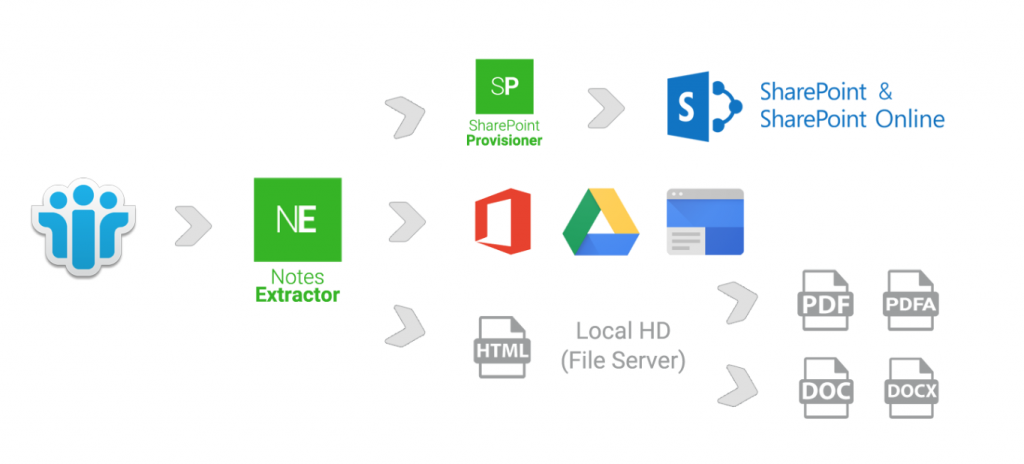
Notes Extractor ist eine Lösung, um die in Notes Datenbanken gespeicherten Daten zu extrahieren und sie entweder in Form von Dateien zu konvertieren, deren Formate den offenen Standards des Marktes (XML, HTML, EML) entsprechen, oder in proprietäre Formate (PDF, Word, SharePoint) , O365, Google Drive, Google Sites usw.).
Das Tool kann alle Notes-Datenbanktypen verarbeiten:
Benutzer-Mail-Datenbanken Generische Mail-Datenbanken, Archivdatenbanken …
Dokumentdatenbanken, die aus einer Standard-Notes-Vorlage generiert wurden (Bibliothek, Forum, TeamRoom …)
Von einer QuickR-Site generierte Datenbanken (Main, Room, Contact, Search).
Domino-Verzeichnisse.
Notes-Anwendungsdatenbanken, auf die entweder über den Notes-Client oder einen Webbrowser zugegriffen wird.
Die Datenextraktion kann auch im Rahmen eines Plattformmigrationsprojekts erforderlich sein, bei dem die Daten aus aktiven Notes-Datenbanken auf andere Anwendungstechnologien (Microsoft SharePoint, Google Apps, Alfresco …) übertragen werden müssen. Die Auswahl offener Dateiformate für den Datenübergang erleichtert den Import in das Zielsystem.
Das Notes Extractor-Tool ist Teil eines größeren Ökosystems zwischen Notes-Datenbank-Audit-Tools (Aktivität, Volumen, Komplexität …) über die Audit Station-Lösung und Tools zur automatischen Datenintegration in Zielsystemen wie SharePoint Provisioner.
Der Notes Extractor-Prozess liest den Notes-Datenbankinhalt, um die Liste der zu konvertierenden Dokumente zu ermitteln. Jedes Notes-Dokument wird in einer Reihe von Dateien extrahiert (ein XML-Dokument + ein HTML-Dokument pro Rich-Text- oder Mime-Feld + angehängte Dateien):

Für jedes Notes-Dokument wird eine XML-Datei erstellt, die alle strukturierten Dokumentdaten (Text, Nummer, Datum, Schlüsselwörter, Identitäten …) sowie Metadateninformationen (ID, Erstellung / Änderung, Uhrzeit / Datum, Größe) enthält …).
Die Dokumentensicherheitsebene (Autoren, Leser, ACL-Rollen) ist in einen eigenen Abschnitt in der XML-Datei integriert.
Alle angehängten Dateien (oder OLE-Objekte) in den Dokumenten werden auf der Festplatte gespeichert.
Unstrukturierte Daten (Rich Text, Mime Part) werden in HTML konvertiert, wodurch das gleiche Erscheinungsbild wie Stile, Tabellen, Farben, Schriftarten, Bilder, Links usw. erhalten bleibt.
Wenn das Dokument angehängte Dateien (oder OLE-Objekte) enthält, ruft das Programm diese ab und trennt sie von der Festplatte. Angehängte Dateien werden extrahiert und im Originalformat gespeichert.
Alle Bilder werden in JPEG-, GIF- oder PNG-Dateien konvertiert. Um Speicherplatz zu sparen, faktorisiert Notes Extractor Images (Einzelinstanzspeicher).
Formulare werden in XSL-Dateien konvertiert.
Ansichten werden erstellt, um alle Dokumenttypen aus der konvertierten Datenbank anzuzeigen. Ansichtsindizes werden als XML- oder HTML-Dateien gespeichert.
Wenn das Dateiformat EML (Mail-Datenbank-Konvertierung) sein soll, wird ein zusätzlicher Durchgang durchgeführt, um XML / HTML-Dateien in EML zu konvertieren.
Features
XML für strukturierte Daten (Text- / Zahlen- / Datumsfelder) und Dokumenteigenschaften (Erstellungsdatum, ID, Sicherheit …).
HTML für Rich Information (Rich Text oder Mime) mit Erhalt von Stilen, Tabellen, Grafiken, Abschnitten, Tabs, Links …
GIF / JPEG / PNG für Bilder (einzeln gespeichert: Single Instance Storage).
EML für Nachrichten.
XSL für Datenanzeigeelemente (Form).
Angehängte Dateien und OLE-Objekte werden direkt von der Festplatte getrennt.
Um die Informationen zur Sicherheit von Notes-Dokumenten (Lesen, Ändern, Löschen) zu erhalten, können Benutzeridentitäten (Notes-Namen vom Typ FullName) entsprechend dem Zielverzeichnis (UPN für Active Directory) übersetzt werden. Notes Extractor übersetzt auch die Namen der in Dokumentfeldern vorhandenen Gruppen und analysiert die Datenbank-ACLs, um [Rollen] zu lösen.
Die Indizes der Ansichten und Ordner der Notes-Datenbanken werden als XML- oder HTML-Dateien exportiert, sodass die Informationen zur Dokumentstruktur erhalten bleiben.
Wenn die exportierten Notes-Datenbanken über eine bekannte Vorlage verfügen (Mail, QuickR, Library, TeamRoom, Forum database …), werden die für die Datenanzeige verwendeten Gestaltungselemente (Browser, Ansichten, Formulare) standardmäßig im Notes Extractor-Produkt bereitgestellt (als XSL-Dateien). . Wenn die Datenbanken eine unbekannte Vorlage (Anwendungsdatenbank) verwenden, konvertiert Notes Extractor Datenbankformulare und -ansichten automatisch in XSL-Dateien, um die Anzeige von Dokumenten zu ermöglichen.
Das Konvertierungsergebnis kann lokal mit einem Webbrowser (Internet Explorer, FireFox, Chrome) oder direkt auf einem Webserver integriert werden. Auf diese Weise erfolgt die Navigation in der Anwendung im schreibgeschützten Modus. Der Ergebnisdateibaum kann auch mit speziellen Tools in Anwendungsarchitekturen wie Microsoft SharePoint, Google Apps, Alfresco usw. eingefügt werden.
Benefits
Notes Datenbanken können einzeln oder als Gruppe konvertiert werden (alle Datenbanken von einem Server oder einem Unterverzeichnis …).
Das Tool passt sich an den Datenbanktyp (Mail-Datenbank, QuickR, Bibliothek, TeamRoom, Anwendung …) an, um eine geeignete Extraktion bereitzustellen.
Die Wahl des Ausgabeformats (XML / HTML oder EML) ist für Mail-Datenbanken möglich.
Während der Extraktion gehen keine Informationen aus Dokumenten verloren (Beibehaltung von Dokumentfeldern und -eigenschaften in der XML-Datei, die für jedes Dokument reserviert ist).
Aus Datenbanken extrahierte Daten können direkt über die Nur-Lese-Zugriffsschnittstelle (mit einem Webbrowser) abgerufen werden.
Die Dokumentensicherheit wird gewahrt (jedes Dokument gibt an, wer schreibgeschützt, modifiziert und gelöscht darauf zugreifen kann).
Benutzeridentitäten werden in das Zielverzeichnis konvertiert (eine Notes FullName-Identität wird zu einem Active Directory-UPN).
Kein Verlust von OLE-Objekten, da diese in Standarddateien (Excel, Word, PowerPoint …) umgewandelt werden.
Rich-Dokument-Abschnitte (Rich-Text- oder Mime-Felder) werden unter Beibehaltung ihres Erscheinungsbilds (Stil, Tabelle, Abschnitt, Tabulatortabelle …) konvertiert.
In Dokumenten vorhandene Links (Datenbanklinks, Dokumentenlinks) werden als URLs übersetzt.
Die Dokumentenstruktur bleibt erhalten (Präsenz in Ansichten, in Ordnern).
Für die Dokumentanzeige verwendete Gestaltungselemente (Browser, Ansichten, Formulare) werden in das HTML / XSL-Format konvertiert, um die gleiche Anzeige der Dokumentdaten wie in der Notes-Datenbank zu ermöglichen.
Das Daten- und Entwurfsausgabeformat verwendet offene Formate (XML / HTML / XSL). Dateien können problemlos angepasst werden.
Möglichkeit, ein Suchmodul für alle Arten von Datenbanken zu verwenden, sodass Informationen nur zum Lesen gefunden werden können.